

一個Web3投資者看ChatGPT和AGI
時間:23-05-31 來源:高山書院
一個Web3投資者看ChatGPT和AGI
近期聽了陸奇博士和張宏江院士關于大模型和 ChatGPT 的分享,收獲很大。整理了一些感想,和 Web3 從業者共勉:
1. 和家里寵物待的時間足夠長,你會意識到貓只是比你簡單幾個維度的一個大模型或者說模型組合。
2. 模型的演化會很像基因和生命的演化,本質是一樣的。Transformer 模型架構的出現就像分子第一次“無意”搭成了可復制的 RNA ;GPT-1、2、3、3.5、4,以及后面的模型發展演化只要沒有慧星撞地球般的事件,可能就像生命爆發一樣,越來越快,越來越“失控”。模型自身有不斷復雜化的“內驅力”,這是宇宙規律。
3. 三十多年前,史蒂芬·平克發現了語言是人類的本能,就像我們現在意識到,原來文字語言能力才是模型訓練里我們苦苦追求的泛化能力的來源。
為什么以前搞人工智能和語言研究走不通,因為路走反了!語言是人大腦神經元系統足夠復雜之后涌現出來的本能,至于是演化成漢語、英語還是鳥語,和環境及部落有關。
泛化模型加上其他“模型”疊加產生了人這個“牛逼”的智能體。你要去主動設計和構建智能體或者 AGI,那就是路徹底走反了。我覺得可能也不是不行,而是要難 1 億倍。
4. 如果我們這個宇宙“上面”有高維智能體或者“神”存在,當它看到地球上的寒武紀大爆發時的驚訝應該像今天我們看到 ChatGPT 一樣。暫時無法完全解釋,只能慢慢體會和學習,試著去了解。
5. AGI可拆解為Reason、Plan、Solve problems、Think abstractly、 Comprehend complex ideas 和 Learning。GPT4 目前除了 Plan 不行,Learning 算一半以外(因為基于預訓練模型,不能實時學習),其他都已具備。
6. 人腦的平均學習能力進化速度緩慢,但硅基智能的發展一旦方向找對,速度可以是指數級的(看下 GPT4 和 GPT3.5 的差距)。
7. 大模型=大數據+大算力+強算法。全球只有美國和中國可以做。做大模型的難點在于芯片,CUDA( GPU 的編程平臺)開發者積累,工程構建,和高質量的數據(用于訓練,調參和對齊)。對齊有兩方面,一是對齊人類大腦的模型和表現方式,二是人類的道德標準和利益。
國內至少有兩個方向的垂直模型賽道很有機會:醫療和教育。
8. GPT4 雖然還有弱點和缺點,但就像人腦一樣,一旦給予更明確的指示或提示,可以更強,調用其他輔助工具后還可以更加完美。就像人腦也需要借助計算器等工具完成人腦本身不擅長的任務。
9. 大模型的參數量應該和人大腦神經元的突觸數相比(而不是神經元),這個數字是100 萬億。GPT4 的參數量還沒有公布,但估計大模型參數量很快會逼近。
10. GPT4 目前的幻覺率( hallucination )大概在 10%-14%,必須降下來。幻覺率是“類人”模型必然會出現的特征。這個比例和人相比,還是太高。能否有效降下來,決定幾年后 AGI 發展是繼續一路向上還是進入階段性低谷期。
11. 對我個人來說,ChatGPT 最大的意義在于它最直接、毫無爭議地證明了基于簡單的計算節點和函數,只要數量足夠多,模型足夠大,就可以生成足夠復雜的思考模式,而這個系統是有限的,不是無限的。
人類語言以及驅動語言的思考的背后可能并不是什么靈魂,可能就是 100 萬億的神經突觸連接后,被環境的演化不斷調教,“涌現”出來的東西。這一切非常符合人類最近兩百年對“人來自于哪里”這個問題的突飛猛進般的各類研究。
12. 單細胞到人的形成,所有證據鏈條已經足夠完備;關于復雜系統的形成,基因的存在和“動機”也已有完備的理論;但人能不能依據所有科學理論,設計出硅基的 AGI 呢?
有人認為是幾年,有人認為是幾十年,更多的人認為永遠不會(即使在看到 AlphaGo 在圍棋領域的表現后),但 ChatGPT 用鐵一般的事實給出了最明確的答案。Sam 團隊應該打心眼里沒覺得人類大腦有什么了不起,才能如此堅定地走大模型的AGI路線,一個月燒1億美元還是很考驗信念的。
13. 由于底層硬件不同,所以 ChatGPT 的“策略”很可能和人的大腦是很不同的,而且是低效的,但令人驚訝的是,“Her” 產生的結果是如此像人的思考。人的思考本質上可能就是由簡單規則驅動的。
14. 語言和思考的“規則”,可能并不是我們能夠完全按“語法”總結出來的,這個規則目前來看是隱含,無法完全簡約和總結的。所以目前只能用大模型來干出來,畢竟人的大腦架構也是從單細胞自然演化來的,即使有造物主,也應該是“開辟”了宇宙后,就撒手不管了,否則怎么會有這么多的 bug 和缺點,哈哈。
15. 我很佩服史蒂芬·平克,他可以在幾十年前只用觀察和推理,就令人信服地說明語言是所有人類的本能,是“刻”在我們基因里的。我不知道 Sam 有沒有讀過《語言本能》這本書,但他證明了 ChatGPT 這樣的人造網絡可以非常好的完成語言創立工作。
語言本能和邏輯思考沒有想象中的復雜,ChatGPT 已經“默默地”地發現了語言背后隱含的邏輯。語言也會是所有硅基 AGI 區別其他硅基計算器和AI的“本能”。
16. 人腦和碳基大腦都喜歡做 generalize 提煉(可能是殘酷的進化所逼),所以極其高效(能量使用方面);但不擅長做 irreducible 的計算和處理,而我們知道很多計算模式可能只能一步一步做。
GPT4 的架構肯定還不是最優,沒有太多的 generalization 和簡化,所以能耗極高。但“此路可通”的全球共識已經形成,后面應該會看到美國和中國的多個團隊在各方面加速推進:芯片算力,數據質量,算法優化,和工程架構等。
17. 人的大腦的價值評估體系應該是碳基分子形成的 DNA 和遺傳基因“為了”最大化地提高自己的復制概率,通過自然演化的力量,給神經元的突觸設置好權重,逐步演化確定下來。
這個碳基計算節點支撐的“模型”遠非完美,演化速度緩慢,“權重”和“算法”調整極其低效,完全跟不上環境變化。所以我們才會有各種宗教提到的人的欲望和痛苦。
18. Why Buddism is True 一書里提到,人大腦至少有7個模塊(應該是多模態并行大模型)。哪一個思維模塊占據“當下”的主體,人的“決策”如何做出,其實都由“感覺”決定。而這個“感覺”就是由“人”進化帶來的“陳舊”的價值評估體系來決定(載體之一可能是腸道細菌,哈哈)。建議大家可以讀下我幾年前寫的讀書筆記的第 6,7,9 部分。
19. 暢想一下,如果人類真的把硅基 AGI 和機器人創造出來了,驅動機器人大腦的價值評估體系是什么?機器人會不會也很困惑“我來自于哪里,我往哪里去”?人類有釋迦摩尼,機器人為什么不能有?機器人覺醒會是怎樣?某個機器人會不會某天寫一本 Why Machinism is True 來呼吁機器人覺悟,呼吁機器人進入涅槃,來擺脫人類給他們設置的“輪回”?
20. 能量限制會是模式演化的硬頂。但未來硅基 AGI 的能量消耗模式應該會比現在高效很多,碳基人腦的模式畢竟迭代演化了十億年,才到了烏鴉大腦般的能量高效。
未來硅基 AGI 的能耗可能是現在人類能使用能量的幾億倍甚至更高量級,但能處理的計算和完成的事情也會是幾億倍。可能可控核聚變技術信手捏來了也不一定。這樣的話,地球上的能量可能就夠了,更何況還有太陽系,銀河系和更廣袤的宇宙。
ChatGPT 和 AGI 很偉大,應該說超級超級偉大!我們有幸活在這個年代,不但肯定能搞懂人來自哪里,可能還能搞懂人往哪里去。
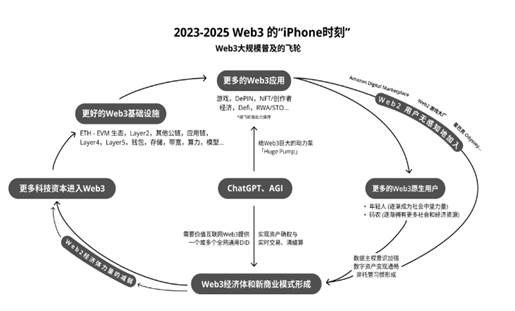
AI的快速發展,會極大地促進我們對 Web3 技術的需求:內容創作如何確權;如何確立人的身份(Sam在搞worldcoin);Prompt 和開源代碼能否做成NFT授權使用;價值如果不能在互聯網上自由流動,生產力那么強有什么用?你能想象所有的內容訂閱,還要用銀行體系來完成轉賬和跨境劃款嗎?你能給一個物聯設備開銀行賬戶嗎?你能同時給 1 萬個用戶轉 0.01 分美元嗎?...我上次說接下來三年是 Web3 的 iPhone 時刻,Web3 用戶三年后肯定能突破1億,甚至遠遠超過。大家可以看我們畫的飛輪:
一直很喜歡看生命科學,復雜系統,(作為哲學的)佛教方面的書籍,推薦幾本給大家,按我個人建議的閱讀次序:《生機勃勃的塵埃》,《奇妙的生命》,《自私的基因》,《自下而上》,The Social Conquest of Earth,《語言本能》,《深奧的簡潔》,《失控》,和 Why Buddism is True。我覺得這些作者如果還健在,還有能力寫,都應該看著 GPT 未來的發展,把書都寫個新版。
人的生命太短暫,很多偉大的想法都極其可惜地永遠地遺失在了歷史的長河里。書籍,音樂和影視的記錄應該只是很小很小的一部分。即使記錄下來,那么多的偉大的著作和真理其實一直都在那里,但一個人又能讀多少呢?硅基 AGI 則完全沒有這個問題。
是時候再把電影 The Matrix 里 Mopheus 和 Neo 的對白找出來再讀一遍了。
摘自-高山書院
| 上一篇 | 下一篇 |
|---|---|
| A股亂紀元 | 沒有上一篇 |
