

朱嘯虎:AI的賺錢風(fēng)向, 徹底變了!
時間:24-06-28 來源:i黑馬
朱嘯虎:AI的賺錢風(fēng)向,
徹底變了!
從去年3月起,生成式 AI 這波浪潮,讓很多人看到中國AI技術(shù)明顯落后于美國,所以大家都很焦慮。
在焦慮背后,很多創(chuàng)業(yè)者盲目投資AI底層技術(shù)。雖然創(chuàng)造了“百模大戰(zhàn)”的盛況,但也造成了社會資源浪費,今年很多大模型創(chuàng)業(yè)公司都遇到了經(jīng)營難題。
很顯然,AI創(chuàng)業(yè)的賺錢風(fēng)向,已經(jīng)徹底變了。
現(xiàn)在,中國經(jīng)濟正在進入一個新的周期,也就是從PC互聯(lián)網(wǎng)、移動互聯(lián)網(wǎng)經(jīng)濟進入AI經(jīng)濟。
周期既是機遇也是挑戰(zhàn),把握商業(yè)大勢、乘風(fēng)前行,是每個創(chuàng)業(yè)者都需要掌握的能力。
01
AIGC創(chuàng)業(yè)回歸商業(yè)本質(zhì)
最近有個特別明顯的感覺:今年將是AIGC創(chuàng)業(yè)回歸商業(yè)本質(zhì)的開始。
沒有良性商業(yè)模式的持續(xù)輸血,單獨的大模型公司很難走遠。
沒有專有數(shù)據(jù)、專有用戶場景來形成數(shù)據(jù)閉環(huán)并持續(xù)優(yōu)化的獨立大模型公司,很難保持持久的防御壁壘。
美國一線大模型公司中,前面四家確實融了很多錢,而且每一家都抱了大腿。而美國二線大模型公司,現(xiàn)在或許還有收購團隊價值,明年可能就毫無價值了。
大廠只為挖AI人才的并購,可能很難給出很高溢價。
比如,Inflection 曾是一個獨角獸企業(yè),微軟投了差不多 15 億美金。最近,他們整個團隊基本都被微軟挖走了。3萬億美金市值的微軟,去收購一家企業(yè),只給了投資人一個本金加利息的退出回報。這是今天在美國發(fā)生的事情。

在國內(nèi),大模型公司正在打價格戰(zhàn),將近幾十萬的漢字,只需要花一塊錢,幾乎是免費的,明年可能就完全免費了。
對大廠來說,他們希望借助低定價來推廣自己的算力和云服務(wù)。你買我的云服務(wù),我免費讓你調(diào)用大模型的 API 。但大廠的這個定價,對創(chuàng)業(yè)大模型公司來說,已經(jīng)是成本線以下。結(jié)果,幾乎沒有一家創(chuàng)業(yè)大模型公司敢跟進。
所以,沒有良性商業(yè)模式的持續(xù)輸血,單獨的大模型公司很難走遠。
今天比較有意思的一點是,中國大廠自己的親兒子,第一次比養(yǎng)子做得更好。
一般來說,中國互聯(lián)網(wǎng)大廠都是自己團隊?wèi)?zhàn)斗力不行,比不上創(chuàng)業(yè)公司,才會戰(zhàn)略投資一些創(chuàng)業(yè)公司。雖然阿里之前投了 5 家大模型公司,但是通義千問的表現(xiàn)比自己投的那五家公司都要強。這也讓大模型創(chuàng)業(yè)公司越做越難。
前兩天,蘋果剛發(fā)布了自己的AI功能。蘋果手機用戶不需要注冊,就可以使用 OpenAI 的 ChatGPT 服務(wù)。
這后面隱藏的含義是:我不給你導(dǎo)用戶,但用戶還是我的。而且,后臺可以隨時切換其他大模型。
據(jù)說Google正在和蘋果公司談,在蘋果手機上預(yù)裝Gemini 大模型要花多少錢。畢竟Google 每年要給蘋果 100 多億美金,就為了 iPhone 上默認(rèn)搜索是 Google。
當(dāng)下,Gemini 確實比 GPT- 4 差那么一點點。但如果 GPT-5 今年不出來,Gemini 到年底追上 GPT-4, 基本上是可以肯定的。
到時候,蘋果手機后臺到底多少給 OpenAI,多少給Gemini,甚至多少給蘋果自有的大模型,還不好說。
所以,我們講“價值微笑曲線”,左側(cè)是英偉達,今天賺了所有的錢;右側(cè)可能是微軟、蘋果這種應(yīng)用型的公司;最底下的可能才是大模型公司。
02
AI不是萬能藥
現(xiàn)在很多人都覺得生成式 AI 是個萬能藥,自己的產(chǎn)品加上AI就很好賣了,但事實上并不是這樣。
最近一些中國做消費電子的企業(yè)加了 AI 后,都覺得消費電子產(chǎn)品變得很智能了,但實際體驗和期望的差距還是很遠。包括美國也是一樣的,雖然AIGC看上去很像驚艷,但真正落地上并不容易。
為什么AIGC很難落地?最主要就兩個問題:一是幻覺問題;二是結(jié)果不可控。
一旦AI有幻覺就會出錯,而且你不知道什么時候會出錯,每次結(jié)果還都不一樣,所以結(jié)果不可控。

隨著大家對幻覺的研究越來越多,發(fā)現(xiàn)造成幻覺的核心問題是臟數(shù)據(jù)。很多訓(xùn)練大模型的數(shù)據(jù)都來自于公開的互聯(lián)網(wǎng),里面很多數(shù)據(jù)并不正確。
上個月谷歌就鬧出一個笑話:
你精心準(zhǔn)備好所有材料,把披薩放進烤箱,期待著美味的晚餐。但當(dāng)你迫不及待地準(zhǔn)備咬上一口時,卻發(fā)現(xiàn)奶酪掉了下來。你感到沮喪,于是上網(wǎng)求助谷歌。
谷歌回答道:“加點膠水,混合大約1/8杯的膠水和醬汁。無毒膠水會更有效。”
這個回答其實是網(wǎng)友在十多年前編的一個笑話,但大模型覺得這是正確的。
03
中國AI技術(shù)不比美國差
更重要的是數(shù)據(jù)
這次去硅谷,當(dāng)?shù)氐膭?chuàng)業(yè)者也很懷疑 GPT-5 年底究竟能不能出來?即使出來了,相較GPT-4,推理能力上會不會在有顯著提高?
現(xiàn)在硅谷都說可能至少要十萬張 ,甚至二三十萬張 GPU 卡,才能看到顯著的性能提升。但是即使你有卡,可能也沒那么多可用來訓(xùn)練的數(shù)據(jù)。
最近快手發(fā)布的「可靈」,大家體驗過嗎?「可靈」做的文生視頻比Sora更好。
為什么快手比 OpenAI 做的還要好?因為快手本身就做短視頻,有很多數(shù)據(jù)做訓(xùn)練。相反,你問Sora 有沒有爬 YouTube 的數(shù)據(jù)做訓(xùn)練,他都不敢說。
快手證明了,卡多還不如數(shù)據(jù)多更有效,我用更多數(shù)據(jù)反而能訓(xùn)練出更好的模型。
所以,中國在 AI 技術(shù)上并不比美國差,而且更重要的是數(shù)據(jù)。
現(xiàn)在,GPT-4 在很多文字場景上,已經(jīng)可以滿足大部分需求,最大的難點是多步推理還不太行。一個比較復(fù)雜的邏輯需要多步推理,如果每一步都只能做到 90% - 95% 的準(zhǔn)確率,那多步迭代后其準(zhǔn)確率可能就到 50% 以下了。
而中國企業(yè)用私有數(shù)據(jù)化訓(xùn)練模型,就可以很大程度上降低幻覺、增加正確率,關(guān)鍵是你有沒有能積累足夠多的高質(zhì)量數(shù)據(jù)。
為什么做微信營銷的公司,去年很容易就用大模型取代了 50% 的人?就是因為他們內(nèi)部把團隊和用戶之間的對話數(shù)據(jù)都累積下來了。
04
中國缺的不是技術(shù)
而是“讓人尖叫”的用戶體驗
在蘋果發(fā)布會上,還重新定義了兩個事情:一是重新定義了什么叫AI?二是蘋果展示了什么叫“入口為王”?

對大部分企業(yè)來說,核心不是AI技術(shù),而是用戶體驗。
怎么把用戶體驗做好是最難的,也是蘋果比較擅長的。
最近和創(chuàng)業(yè)黑馬學(xué)員在硅谷,有人說特別看好 AI 賦能消費電子、 AI 寵物。確實,最近做消費電子+AI 的企業(yè)特別多。
但很可惜,我覺得體驗都沒有到那一步。我買了一個 AI 寵物狗,還沒那么智能,基本還差了一個時代。
你想讓消費者愿意買單,一定要做出讓消費者覺得尖叫的點,這個點是非常不容易的。
什么是入口為王?我前面講過,蘋果雖然選擇了OpenAI,但是不給OpenAI倒用戶。其次我在后臺是可以隨時切換大模型。
我們在硅谷的時候,有內(nèi)部消息說,蘋果后臺可能 70% 用ChatGPT,30%用Gemini 。到年底如果 Google更愿意給錢的話,很有可能是 70% 用Gemini , 30% 用ChatGPT。
對大部分創(chuàng)業(yè)者來說,一定要是聚焦垂直場景,做通用大模型幾乎已經(jīng)沒有價值了。
05
聚焦垂直應(yīng)用
場景優(yōu)先,數(shù)據(jù)為王
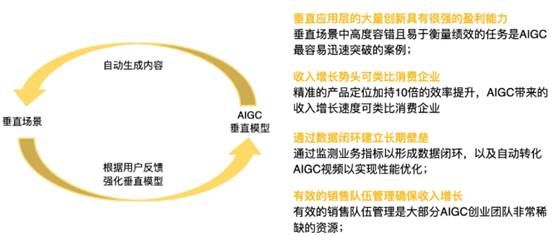
現(xiàn)在通用大模型基本上是巨頭的天下了,但中國的垂直場景特別豐富,數(shù)據(jù)也特別多,所以一定要聚焦在垂直場景上。
先給大家分享一個案例,有一家給中國電廠做信息系統(tǒng)維護的公司,他們找到的場景特別有意思,就是派工單。
電網(wǎng)維護本身是一個高風(fēng)險的工作,很容易出事故,一旦出事可能就是人命關(guān)天的事。以前電廠維護電網(wǎng)派工單,每個工單中可能包含兩三百個步驟,派一個單子至少要兩三天的時間,還得人工反復(fù)核對。
他們?nèi)ツ昊藘扇齻€月,讓大模型把過去幾年派過的工單全部學(xué)習(xí)了一遍,將派單時間一下縮減到了2分鐘。半年后發(fā)現(xiàn),大模型比人設(shè)置的準(zhǔn)確度更高。
你看,像這種垂直場景外行根本拿不到,只有你聚焦在細(xì)分行業(yè)里,才能找到這些機會點。
一旦找到這種尖刀場景,就盡快建立數(shù)據(jù)閉環(huán),先把客戶圈下來。

對創(chuàng)業(yè)者來說,找到好場景根本不需要你投很多錢,你10個人找不到好場景,投100 個人來也是浪費。所以,很多企業(yè)說我要砸?guī)浊f,建立 100 人、 200 人的隊伍去做AIGC,根本是錯誤的。
還有一家深圳公司叫HeyGen ,后來搬到了美國,他做的就是非常簡單的數(shù)字人。場景很簡單,以前在抖音或Tiktok上發(fā)短視頻,都要真人反復(fù)錄制,很花時間。
今天用數(shù)字人,只需要上傳幾張照片,再輸入視頻文案,就可以自動生成一分鐘的短視頻。現(xiàn)在國內(nèi)的數(shù)字人已經(jīng)是白菜價了,但在美國還可以賣得很好。就這么一個簡單的產(chǎn)品,很短時間內(nèi)就做到了年入3500萬美金。
所以,要迅速開發(fā)最小可行產(chǎn)品MVP,快速試錯和迭代。HeyGen半年之內(nèi)就迭代 30 個版本。
找到好場景后,關(guān)鍵是測試用戶愿不愿意買單,只要用戶愿意買單,你可以做得更深、更厚。
我覺得,今天這波生成式 AI 浪潮中,中國企業(yè)并不比美國落后多少。尤其是今年,如果到年底 GPT-5 出不來,明年開始拼應(yīng)用的時候,中國在應(yīng)用層會比美國要領(lǐng)先很多。
我再推薦一個賣得非常好的場景。現(xiàn)在中國直播電商非常火,尤其像 618大促的時候,直播進來的用戶很多,以前客服人員根本來不及回復(fù),會浪費很多商機。
現(xiàn)在靠 AIGC 機器人在直播間自動回用戶的提問,這種產(chǎn)品賣得非常好。這個場景看著非常簡單,但是特別痛。這種場景一是好訓(xùn)練,用以前的產(chǎn)品描述和對話記錄來訓(xùn)練垂直大模型,很容易避免幻覺;二是能容錯,稍微有誤差也不那么敏感。
很多垂直行業(yè)的軟件只要找到痛點場景,加上 AI 功能是容易的。因為你積累的垂直數(shù)據(jù)就是你的優(yōu)勢。反過來,AI 創(chuàng)業(yè)公司想快速找到好場景和垂直數(shù)據(jù)就很難。
06
AIGC將是未來10年的長坡厚雪
最近,英偉達市值登頂全球第一,就跟過去20年很像。PC 互聯(lián)網(wǎng)、移動互聯(lián)網(wǎng),每一波新周期開始時,都是半導(dǎo)體硬件技術(shù)設(shè)施漲得最好。
早在 2000 年,思科也曾是當(dāng)時全球市值第一的超級公司。但很快又被谷歌、蘋果、Facebook、亞馬遜等應(yīng)用層公司超越,這些公司創(chuàng)造的價值是前者的10倍。
再加上,在很多場景下,很多國內(nèi)的開源模型已經(jīng)不比閉源模型差了,完全足夠支撐中國AI應(yīng)用的發(fā)展。
尤其在中文知識方面,阿里的通義千問比Llama 3還強。所以,很多創(chuàng)業(yè)公司都是拿 1000 萬參數(shù)的開源模型來訓(xùn)練自己的垂直模型。

我認(rèn)為,AIGC將是未來10年的長坡厚雪,應(yīng)用層將創(chuàng)造最多的價值。
未來十年,AIGC會把所有軟件、消費電子和消費端的應(yīng)用都重新做一遍,這里面有很多機會。
最后,送給所有的創(chuàng)業(yè)者三句話:
1、不擁抱AI的企業(yè)肯定會被淘汰。
2、不要迷信AI,聚焦尖刀場景盡快落地。
3、優(yōu)化用戶體驗,閉環(huán)數(shù)據(jù),不要投入底層技術(shù)。
摘自-i黑馬
| 上一篇 | 下一篇 |
|---|---|
| 中國經(jīng)濟面臨前所未有的四大 歷史性難題 | 沒有上一篇 |
